从零入门 cuda 编程?🦴 看这篇就够了!
实录:从零开始接触 cuda 编程 🐟
CUDA(全称 Compute Unified Device Architecture,中文译为“统一计算设备架构”),由 nvidia 在 2007 年发布,提供用于编程和管理 GPU 的 C/C++ 语言扩展和 API,服务于 GPU 通用计算,时至今日已历经十几年演进。本博客记录对 CUDA 的学习过程,重点内容包括:
- CUDA 的架构详述,包括:硬件、软件和各种常见术语。
- CUDA 的安装、编译工具和编辑器的配置。
- CUDA 的基础语法:函数标识符、变量标识符、内置向量类型和内置变量、执行配置。
- CUDA 的 Runtime API:内存和线程管理、设备管理、事件管理、流管理。
- CUDA 编程实例:测试 GPU 的乘加性能。
详解 CUDA 架构:软件层和硬件层相结合
在 CUDA 中,GPU 作为 CPU 的协处理器工作。通常,我们将 CPU 和 GPU 系统分别称为 主机(host) 和 设备(device) ,它们是具有各自内存空间的独立平台 📚。一般地,我们在 CPU 上运行串行工作负载,并将并行计算卸载到 GPU 上。
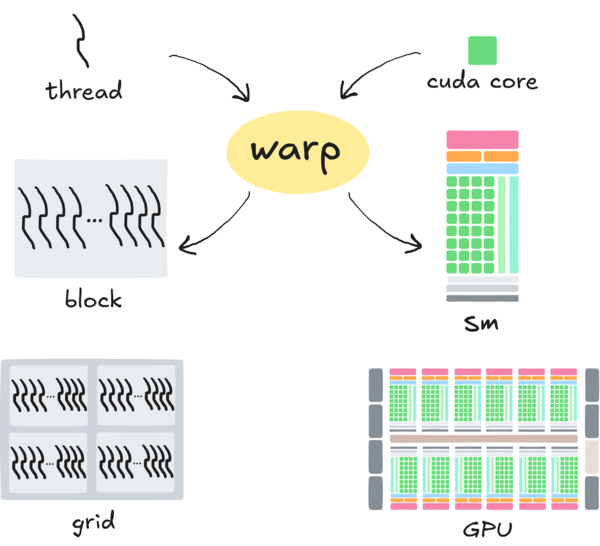
CUDA 的架构包括软件层和硬件层,如上图所示。软件层包括:线程 (thread),线程块 (block) 和 网格 (grid) 。硬件层包括:CUDA 核心 (或称流处理器,也即 SP),流式多处理器 (SM, streaming multiprocessor) 和 GPU。除这些以外,还有 线程束 (warp) ,它充当沟通硬件层和软件层的桥梁。
线程和 CUDA 核心:最小的基本运算单位
线程 (thread) 🧶
线程是对计算机中 程序执行流 的形象比喻,它由 指令流 和 数据流 交织构成,是 GPU/CPU 通用的原子级概念。在 CUDA 中,线程按束调度: 同束线程共享相同的程序计数器 ,它们同步地执行相同的指令,作用于各自寄存器存储的数据。
CUDA 核心 (SP)
CUDA 核心是 CUDA 中执行标量运算指令的基本单元,其核心组件是 整数运算单元 (INT) 和 浮点数运算单元 (FP) 。CUDA 核心和线程相对应:单个 CUDA 核心执行来自单个线程的指令 。与线程相同,CUDA 核心同样按束调度: 同束核心在同一时刻执行相同的指令 ,但作业于不同的寄存器。

单指令多线程 (SIMT, Single Instruction MultiThreads)
🪶 这里,我们特别指出:上述线程和 CUDA 核心所采用的“ 多个线程在同一时刻执行相同的指令,但作用于不同的数据 ”的并行方式,即所谓的 单指令多线程 ,这也是 CUDA 所使用的方式。与 SIMT 相对的是 SIMD (Single Instruction MultiData, 单指令多数据),它更像是 vector 架构。
线程块、网格和 Kernel:CUDA 的概念模型
线程块 (block) 🧊 和 网格 (grid) 🥅
线程块是对许多线程的概念抽象,它将数量繁多的线程按照 1 维、2 维或 3 维的方式组织,为开发者遍历、索引线程提供了极大方便。比线程块更高级的概念是网格,它将许多个线程块按照 1 维、2 维或 3 维的方式排列。由此,我们得到了 网格-线程块-线程 的线程层级概念划分。
线程坐标与索引的转换
譬如下图左半部分,对于大小为 $(D_x, D_y)$ 二维线程块,其中索引为 $(x, y)$ 的线程的 块内线程 ID 应当是 $x + yD_x$ 。然而,由于线程块的维度和网格的维度能以各种方式组合,在不同组合下获取线程的全局 ID 或者块内 ID 仍然是一个复杂的问题。
CUDA 内存的读写规则
CUDA 允许设备上的线程以 寻址、共享、缓冲 的方式读取 DRAM 和 On-Chip 内存。更具体的,如下图右半部分,执行在设备上的线程,只允许按如下方式读写内存:1. 读写每条线程的寄存器和本地内存。 2. 读写每个块的共享内存。 3. 读写每个网格的全局内存。 4. 只读每个网格的常量内存和纹理内存。
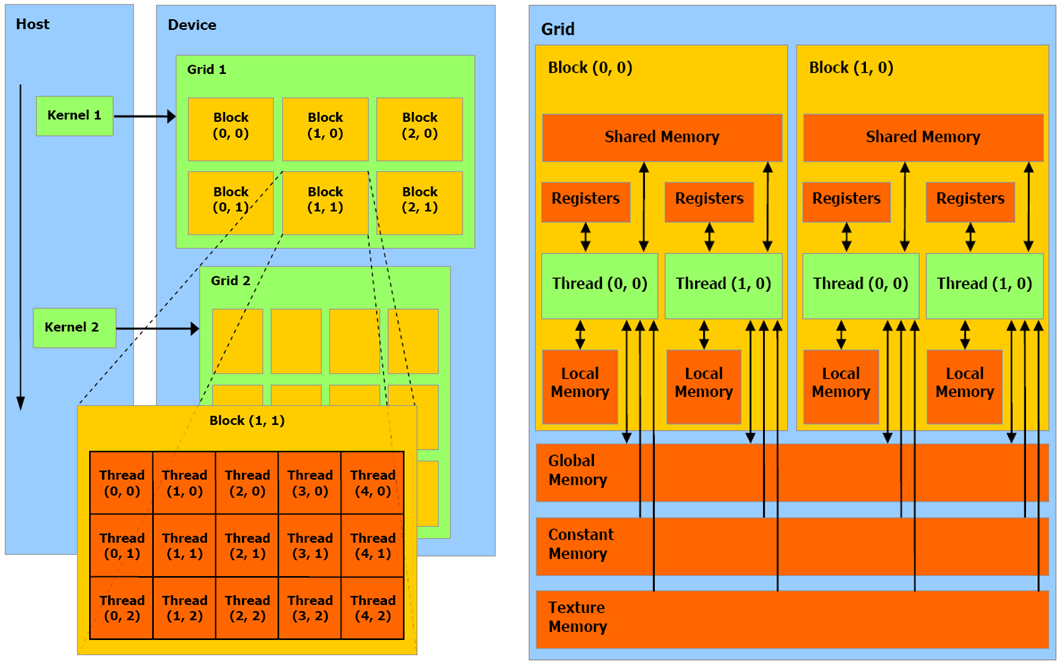
Kernel (核函数) 🥜
特指由主机调用,在设备上运行的函数,它指示了网格内所有线程的行为。 程序运行时,主机向设备连续地发送 kernel 调用的请求,每个 kernel 就作为一个由线程块组成的线程批处理来执行,如上图左半部分所示。单个 kernel 可能由多个线程块执行,线程块内的线程将 共享某块内存,并在必要时同步。
流式多处理器:并行计算的幕后功臣
SM (流式多处理器,Streaming Multiprocessor)
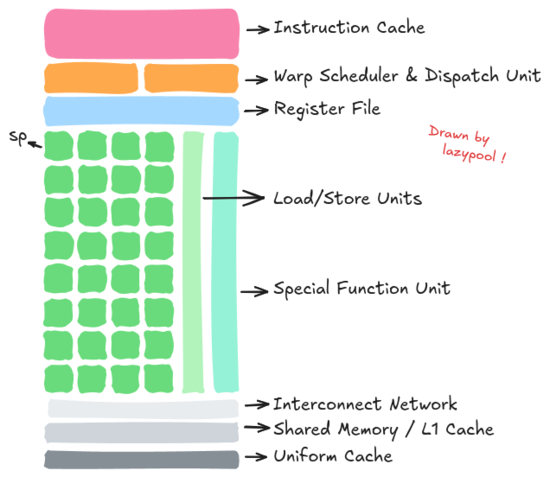
以 Fermi 为例,如下图所示,单个完整的 SM 除了若干个 SP 还应该包括:指令缓存、线程束调度器和分派单元、寄存器文件、加载/存储单元队列、特殊功能单元队列、共享内存/L1 缓存、统一缓存等。它们的作用听名字都能猜出来,感兴趣可以自己去查一下,这里不再赘述 🐈🐕。
线程束:连接软件层和硬件层的纽带
线程束 (warp) 🧵
线程束是真正执行并行操作的单位,通常以 32 个线程为一束。 线程束是连接软、硬件层的纽带,软件层面开发者定义的线程块,通过线程束这一执行单元映射到硬件层面的 SM 上。具体来说,每个线程块在加载到 SM 时,会被划分为若干束,而这些束正是 SM 的实际调度单位。
线程束的并行与同步
同束线程共享内存,在运行时保持同步。束与束之间则保持并行,仅在必要时同步。 束内线程仅 32 个,因此同步的时间开销是可接受的。 线程束的共享内存实际上作为缓存,用于缓存本束的计算结果,然后再上传。 对所有束的计算结果同步汇总的时间也是可接受的。由此,也能知道 CUDA 计算的时间:
$$总时间成本 = 核心计算的时间 + 束内线程同步的时间 + 对各个束进行同步的时间$$
线程束的分化
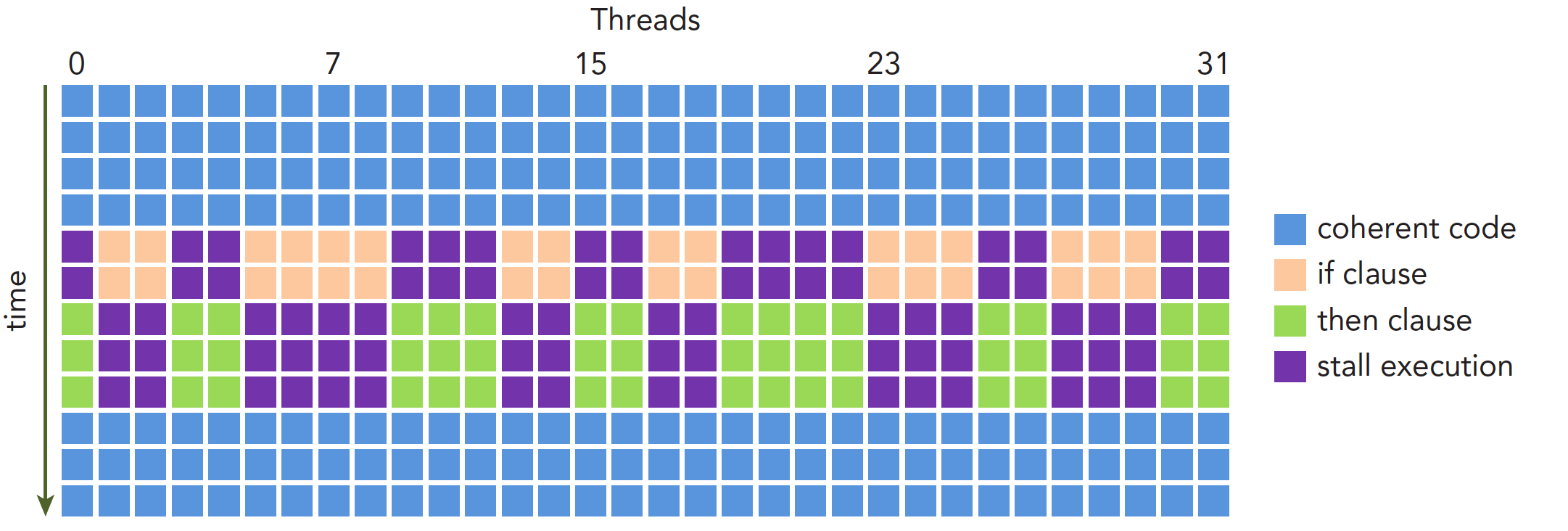
同束线程执行不同指令就叫做线程束分化。 同束线程执行相同的指令,但处理各自的数据。若它们在执行时遇不同的控制条件,就会进行不同的选择,导致线程束分化。分化期间,条件为真的线程将执行指令,为假的线程则空等(stall execution)。线程束分化严重影响性能。条件分支越多,并行性削弱越严重。因此,应尽量避免同束内线程分化,确保线程分配到线程束是有规律的。
正式进入 CUDA 编程:安装、编译器、编辑器
我们花了大量的时间和篇幅详述 CUDA 的软件层面和硬件层面的架构,这有助于我们理解接下来的内容。CUDA 的编程主要围绕 Kernel 展开,我们将会逐步深入对它的理解。在此之前,先下载好 CUDA 的编译器 nvcc。
下载 CUDA 库及编译工具 nvcc
1 | |
配置环境变量
将以下内容添加到 ~/.bashrc 或 ~/.zshrc:
1 | |
然后执行 source ~/.bashrc 或重新登录。
Neovim 启用 CUDA 语法检查
1 | |
基础的 CUDA 语法:C 语言的迷你扩展集
让我们从 Hello World 程序开始,简单比较一下 C 和 CUDA,理解下 CUDA 在实际编程上的特点。
|
C/C++
|
CUDA
|
可以看到主要区别有两点:一是函数声明/定义时使用 __global__,我们将其称作 函数执行空间标识符。二是调用函数时使用 <<...>>,我们将其称作 执行配置。实际上,CUDA 对 C 的扩展可归纳为四点:1. 函数执行空间标识符;2. 变量内存空间标识符;3. 内置向量类型和内置变量;4. 执行配置。
函数执行空间标识符 (Function Execution Space Specifier)
__global__
- 声明一个函数为 kernel,它在设备上执行,从主机调用。
__global__函数必须返回 void 类型,且不能作为类成员方法。- 调用
__global__函数必须给定执行配置。 __global__的调用是异步的,这意味着它会在设备执行完毕前返回。
__device__
- 声明一个函数,在设备上执行,也仅可以从设备上调用。
- 它不能与
__global__标识符同时使用。
__host__
- 声明一个函数,在主机上执行,也仅可以从主机上调用。
- 通常该标识符可以省略不写,默认是主机调用并执行函数。
- 不能与
__global__标识符同时使用。 - 当与
__device__标识符同时使用时,会同时为主机和设备编译该函数。
Undefined behavior (未定义行为)
以下函数调用方式会被编译器解释为未定义行为:
- 在
__global__,__device__或__host__ __device__内调用__host__函数;- 在
__host__函数内调用__device__函数。
其他注意事项⚠️
__device__和__global__函数不支持递归。- 不能在
__device__和__global__函数中声明静态变量。__device__和__global__函数不能有自变量的一个变量数字。- 无法获得
__device__函数的地址,但指向__global__是合法的。
变量内存空间标识符 (Variable Memory Space Specifiers)
默认情况下,未指定标识符的变量会驻留在寄存器上。然而,部分编译器会将其置于本地内存,这会影响并行性能。因此,应当尽可能指定变量的内存空间标识符。
__device__
- 声明一个驻留在设备内存的变量。
- 可与至多 1 个其他的变量内存标识符组合使用。
- 默认行为 (当它单独使用时):
- 位于全局内存空间。
- 生命周期与创建它的 CUDA 上下文相同。
- 每个设备有其独立的副本。
- 可通过 运行时 API 被网格内所有线程和主机访问。
- 适合存储需要全局访问的大规模数据。
__constant__
- 必须与
__device__组合使用。 - 驻留在常量内存空间。
- 生命周期与创建它的 CUDA 上下文相同。
- 每个设备有其独立的副本。
- 可通过 运行时 API 被网格内所有线程和主机访问。
- 主机在并发内核访问时修改常量会导致未定义行为。
- 适合存储只读数据。
__shared__
- 必须与
__device__组合使用。 - 驻留在线程块的共享内存。
- 生命周期与线程块相同。
- 每个线程块有独立副本。
- 仅块内线程可访问,地址不固定。
在 CUDA 中,通过
extern关键字,可使数组大小在内核启动时由执行配置<<<...>>>动态指定。以这种方式声明的所有变量都从内存中的相同地址开始,因此必须通过偏移量显式地管理数组中变量的布局。例如,在动态分配的共享内存中,可以用以下方式声明和初始化数组:
1 | |
注意,指针需与其所指向类型对齐,故而以下代码不能工作,因为
array1没有对齐到声明array时所指定的 float 的 4 字节。
1 | |
内置向量类型和内置变量
内置向量类型 (Built-in Vector Types)
这些是从基本整数和浮点类型派生出来的向量类型。它们是结构体,其第 1、2、3 和 4 个分量分别可以通过字段 x、y、z 和 w 来访问。它们都带有一个构造函数,形式为 make_<type name>;例如,
1 | |
该构造函数会创建一个值为 (x, y) 的 int2 类型的向量。向量类型的对齐要求在右表中有详细说明。
| 类型 | 对齐 |
|---|---|
| char1, uchar1 | 1 |
| char2, uchar2 | 2 |
| char3, uchar3 | 1 |
| char4, uchar4 | 4 |
| short1, ushort1 | 2 |
| short2, ushort2 | 4 |
| short3, ushort3 | 2 |
| short4, ushort4 | 8 |
| int1, uint1 | 4 |
| int2, uint2 | 8 |
| int3, uint3 | 4 |
| int4, uint4 | 16 |
| long2, ulong2 | 8 or 16 |
| long3, ulong3 | 4 or 8 |
| long4, ulong4 | 16 |
| longlong1, ulonglong1 | 8 |
| longlong2, ulonglong2 | 16 |
| longlong3, ulonglong3 | 8 |
| longlong4, ulonglong4 | 16 |
| float1 | 4 |
| float2 | 8 |
| float3 | 4 |
| float4 | 16 |
| double1 | 8 |
| double2 | 16 |
| double3 | 8 |
| double4 | 16 |
| long1, ulong1 | 4 or 8 |
除上面常用的向量类型,CUDA 还提供了名为 dim3 的向量类型。该类型是一个基于 uint3 的整数向量类型,用于指定线程块和网格的尺寸,在后面讲执行配置时我们会看到它的作用。在定义类型为 dim3 的变量时,任何未指定的组件都初始化为 1。
内置变量 (Built-in Variables)
- gridDim :
dim3,表示网格的维度(gridDim.x, gridDim.y, gridDim.z)。 - blockIdx :
uint3,表示网格中块的坐标(blockIdx.x, blockIdx.y, blockIdx.z)。 - blockDim :
dim3,表示线程块的维度(blockDim.x, blockDim.y, blockDim.z)。 - threadIdx:
uint3,表示线程在块中的坐标(threadIdx.x, threadIdx.y, threadIdx.z)。 - warpSize :
int,包含了以线程为单位的线程数的大小。
执行配置 (Execution Configuration)
调用 __global__ 函数必须指定执行配置。执行配置定义了将在设备上执行该函数的网格和块的维度,以及相关的 stream。执行配置通过在函数名和括号参数列表之间插入 <<< Dg, Db, Ns, S >>> 形式的表达式来指定,其中:
- Dg 是
dim3类型,指定网格的维度大小,使得启动的线程块的块数为Dg.x * Dg.y * Dg.z。 - Db 同样是
dim3类型,指定每个块的维度大小,使得每个块具有Db.x * Db.y * Db.z个线程。 - Ns 是
size_t类型,指定每个块为此调用 动态分配的共享内存字节数 。此动态分配的内存用于任何声明为extern数组的变量(如__shared__中所述);Ns是可选参数,默认为 0。 - S 是
cudaStream_t类型,指定相关的流;S是一个可选参数,默认值为 0。
例如,声明为以下形式的函数,必须像这样调用:
1 | |
- 执行配置的参数在实际函数参数之前被评估,以下两种情况将导致函数调用失败:
Dg或Db大于设备允许的最大大小(如计算能力中所指定);Ns大于设备上可用的最大共享内存量减去静态分配所需的共享内存量。
进阶:部分常用的 Runtime API
内存与线程管理
cudaMalloc()
cudaError_t cudaMalloc(void** devPtr, size_t count);
- 在设备上分配 count 字节的线性内存,并将指向该部分内存的指针交给 devPtr。
- 分配的内存适合任何类型的变量。
- 如果分配失败,返回
cudaErrorAlloction。
cudaFree()
cudaError_t cudaFree(void* devPtr);
- 释放被 devPtr 指向的内存空间。
- devPtr 必须被 cudaMalloc() 赋值过,否则会引发错误。
- cudaFree() 可以重复调用,这将不会执行任何操作。
cudaMemcpy()
cudaError_t cudaMemcpy(void* dst, const void* src, size_t count, enum cudaMemcpyKind kind);
cudaError_t cudaMemcpyAsync(void* dst,constvoid*src, size_t count, enum cudaMemcpyKind kind, cudaStream_t stream);
- 拷贝 count 字节,从 src 指向的内存区域到 dst 指向的内存区域。
- kind 可以是
cudaMemcpyHostToHost,cudaMemcpyHostToDevice,cudaMemcpyDeviceToHost,或cudaMemcpyDeviceToDevice的拷贝方向。 cudaMemcpyAsync()是异步的,并且可以作为一个可选参数通过流使用。
cudaDeviceSynchronize()
cudaError_t cudaDeviceSynchronize(void);
- 阻塞,直到设备上所有请求的任务执行完毕。
- 若任何一个任务失败,
cudaThreadSynchronize()都将返回一个错误。
示例:管理设备内存和等待设备执行
1 | |
设备管理 (Device)
cudaGetDeviceCount()
cudaError_t cudaGetDeviceCount(int* count);
- 将计算兼容性大于等于 1.0 的设备数量赋值到 count 所指向的 int 变量。
- 如果没有相关设备,返回 1。
cudaSetDevice()
cudaError_t cudaSetDevice(int dev);
- 指示当前所处的主机线程,使用代码为 dev 的设备。
cudaGetDevice()
cudaError_t cudaGetDevice(int* dev);
- 将当前主机线程所用设备的代码赋值到 dev 所指向的 int 变量。
cudaGetDeviceProperties()
cudaError_t cudaGetDeviceProperties(struct cudaDeviceProp* prop, int dev);
- 将代码为 dev 的设备的属性赋值到 prop 所指向的 cudaDeviceProp 结构体。
- cudaDeviceProp 结构体的定义可参阅 nvidia 文档
示例:获悉设备属性
1 | |
事件管理 (Event)
cudaEventCreate()
cudaError_t cudaEventCreate(cudaEvent_t* eventPtr);
- 创建一个事件对象,它具有 cudaEvent_t 类型,被 eventPtr 指针所指向。
- cudaEvent_t 类型的定义可参考 nvidia 文档
cudaEventRecord()
cudaError_t cudaEventRecord(cudaEvent_t event, CUstream stream);
- 记录事件 event,注意此处的 event 并非指针,而是 cudaEvent_t 类型。
- 如果stream 是非零的,当流中所有的操作完毕,事件被记录。
- 若 stream 为空,当CUDA context 中所有的操作完毕,事件被记录。
- 该操作是异步的,必须使用
cudaEventSyncronize()来确保事件真的被记录。
cudaEventSyncronize()
cudaError_t cudaEventSyncronize(cudaEvent_t event);
- 阻塞线程,直到事件 event 真的被记录。
- 如果
cudaEventRecord()从未被调用过,则返回cudaErrorInvalidValue。
cudaEventElapsedTime()
cudaError_t cudaEventElapsedTime(float* time, cudaEvent_t start, cudaEvent_t end);
- 计算两个事件 start 和 end 之间所花费的时间,并赋值到 time 所指的 float 变量。
- start 和 end 必须都被调用过
cudaEventRecord(),并且已经真的被记录了。 - 否则,将返回
cudaErrorInvalidValue错误。 - 此外,若 start 和 end 中有被带非零 stream 记录的事件,结果将会是 undefined。
cudaEventDestroy()
cudaError_t cudaEventDestroy(cudaEvent_t event);
- 销毁事件对象 event。
示例:测量内核执行时间
1 | |
流管理 (stream)
cudaStreamCreate()
cudaError_t cudaStreamCreate(cudaStream_t* streamPtr);
- 创建一个流对象,它是 cudaStream_t 类型,被 streamPtr 所指向。
- cudaStream_t 类型的定义可参考 nvidia 文档
cudaStreamSyncronize()
cudaError_t cudaStreamSyncronize(cudaStream_t stream);
- 阻塞当前进程,直到设备完成流 stream 中的所有操作。
cudaStreamDestroy()
cudaError_t cudaStreamDestroy(cudaStream_t stream);
- 销毁一个流对象。
示例:异步数据传输
1 | |
CUDA 编程实例:测试 GPU 的乘加性能
利用 cuda 编程测试 GPU 进行乘加浮点运算 c+=a*b 的性能,将其量化成 GFLOPS 指标 (GFLOPS, Giga FLoating-point Operations Per Second,每秒 10 亿次的浮点运算数) ,并呈现 GPU 的部分属性。拟对 $2^{24}$ 个元素进行计算,迭代 100 次。
Cuda 源代码
1 | |
编译及输出
1 | |
可以看到,Tesla K20c 有 13 块 SM,每块最大线程数为 1024,显存 4.63 GB,每秒可执行 184.7 亿次浮点运算。到此,我们已经掌握了入门 CUDA 所需的全部基础知识了!鼓掌👏👏👏