从零入门 cuda 编程?🦴访存优化!
Cuda 的访存优化
继上篇从零入门 Cuda 编程已经 6 个月了,这篇博客已经不能再拖了。我之前早有规划,写完 Cuda 编程入门之后,还要写一篇 访存优化,还要写一篇 执行配置优化,还要写一篇讲 SGEMM 的。这样算是起了一个 Cuda 编程的头,也好后面继续深入。然而,人一旦在学校,做什么事情便由不得自己了。忙完 6 月份,又忙 7、8 月份的保研和秋招,真是让人火大。 总而言之,这一篇是讲访存优化的!
为什么要强调访存优化
让我们回顾一道经典的小学数学题:1 名工人 👷 修建 1 栋房子 🏠 需要 1 年,问 2 名工人 👷👷 修建这栋房子需要多少年?答案是半年。以此类推下去,10 个工人呢?100 个工人呢?…… 我们会发现,单纯地增加工人数量所带来的效率提高有一个上限,或者说 瓶颈。显然,这个瓶颈不是由工人数量决定的,而是由 能真正同时工作的最大工人数量 决定的。
类比到 CPU 和 GPU 里面:假设 CPU 单线程完成某个任务所耗费的总时间为 $T$,那么 GPU 多线程在理想状态下所耗费的最短用时应该为 $\frac{T}{n}$,其中 $n$ 为线程的总数量。然而,有时候线程数量的增加并不一定能够缩短任务用时,它还受三个因素影响: 线程运行至少所需的时间 $t(n)$ 、内存访问总量 $A$ 和当前允许的最大带宽 $B$。 容易看出,实际最短耗时 $h$ 具有如下性质:
$$h\ge\min(\frac{T}{n},t(n),\frac{A}{B})$$
现如今,由于技术迭代,单 GPU 可以开辟的线程数量可以达到万级,所以线程数量 $n$ 往往可以足够大,再加上现在的运算速度越来越快(大于 20 GFLOPS),使得 $\frac{T}{n}$ 和 $t(n)$ 能够很容易降低。于是,相对应地,$\frac{A}{B}$ 成为了性能的主要瓶颈。要设法降低这个值,我们可以选择缩小 $A$ 和提高 $B$,也即:
- 要么,减小内存访问总量 A,这提示我们要通过有效的数据重用来减少内存访问频次。
- 要么,提高当前允许的带宽 B,这要求我们尽可能的缩小内存访问的延迟。
通常来说,数据重用需要一些很 trick 的 idea,而且与问题自身的要求也很相关,所以很难总结出一套“放之四海而皆准”的经验。然而,对于缩小内存访问的延迟,则有一些很通用的基础技巧,可以帮助我们尽量提升数据带宽。 而这篇博客也正聚焦于此。所以,下次有人再和你谈 Cuda 访存优化时,你就知道减小访存延迟也是一种极其重要的措施了。
从代码来看访存发生的时机
📌 通常把主机内存简称作”内存“,把设备内存简称作”显存“,两者互相独立,偶尔互传数据。
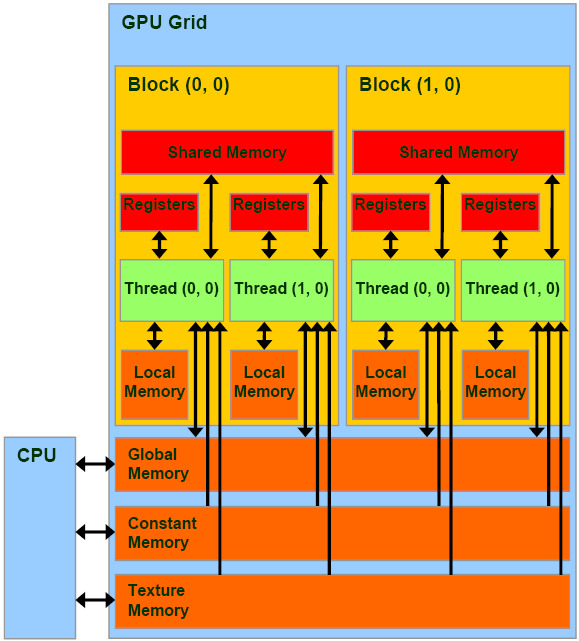
从操作来看,访存包括 读内存 和 写内存。从读写对象看,Cuda 访存包括:内存和显存间的传输、对全局内存的读写、对共享内存的读写、对寄存器的读写、对本地内存的读写。(注意,这里仅列举了最常用到的存储层级,事实上还包括常量内存、纹理内存、L2 内存等,这里不作详细展开。)下列图表反应了 Cuda 内存存储体系的总体架构,以及各存储体系的性质。
| 存储器 | 位置 | 作用域 | 读写级别 | 访问速度 |
|---|---|---|---|---|
| 全局内存 | DRAM | 全部线程 | 读写 | 非常慢 |
| 共享内存 | On-Chip | 同块线程 | 读写 | 快 |
| 寄存器 | On-Chip | 单个线程 | 读写 | 非常快 |
| 本地内存 | DRAM | 单个线程 | 读写 | 非常慢 |
| 常量内存 | DRAM | 全部线程 | 只读 | 慢 |
| 纹理内存 | DRAM | 全部线程 | 只读 | 慢 |
我们最好还是从代码入手,来看访存发生的时机。进行 Cuda 编程特别是程序优化时,一定要对访存发生的时机特别敏感。以下是一份简化后的代码,省略了很多的细节。
1 | |
- 内存和显存间的互传: 这通过
cudaMemcpy函数显式指定,并用cudaMemcpyHostToDevice和cudaMemcpyDeviceToHost来指明方向。 - 对全局内存的读写: 全局内存通常作为核函数的指针参数传递,在上面的例子中即是
int *a。核函数内部对于a的任何读写都是对全局内存的读写。 - 对共享内存的读写: 共享内存需要通过关键字
__shared__指明,在上面的例子中即是int a_s[128]。如果不使用extern关键字,在声明时就需要指明共享内存的大小。核函数内部对于a_s的任何读写都是对共享内存的读写。 - 对寄存器的读写: 核函数内的全部本地变量,在上面的例子中即是
tid和tx。凡是用到tid或tx,或者要修改其变量,就是对寄存器的读写。
内存和显存间的传输
主机内存叫做“内存”,设备内存叫做“显存”,两者是独立的。为了让 GPU 能够向主机内存读或写数据,偶尔需要让数据在内存和显存间进行传输。这条传输的通道即为 PCle。PCle 的带宽很低,约为 16 GB/s,远低于显存 898 GB/s 的带宽。 因此,优化主机与设备间数据传输的核心策略是: 尽可能减少在主机(CPU)和设备(GPU)之间进行数据传输,即使这意味着有相当多的操作将在设备端进行。
为了尽可能地减小内存和显存间的数据传输,常用的办法包括:
- 重新设计算法, 尽可能减少甚至消除不必要的数据传输 ,最小化数据传输。
- 中间数据留在设备端 ,设备内存中创建、操作和销毁中间数据结构,避免写回主机内存。
- 将许多小的数据传输请求合并成一个大的传输,传输后再解包 。即使需要将非连续的内存区域打包成一个连续的缓冲区,其性能也远高于多次单独的小传输。
- 使用固定内存 Pinned Memory 和 Page-Locked Memory。需要注意,固定内存是稀缺资源,且固定操作是重量级操作,应进行测试以确定最佳使用量。
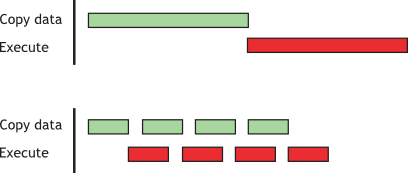
- 使用异步传输重叠计算与传输,使用
cudaMemcpyAsync()进行非阻塞的数据传输。如上图。 - 零拷贝和统一虚拟寻址,这部分功能需要结合实际进行考量,不展开讨论。
全局内存:Coalesced
在为支持 Cuda 的 GPU 架构编程时,一个非常重要的性能考虑因素是全局内存访问的 凝聚性(Coalesced) 。所谓凝聚性,或者合并访问,是指同一个 warp 的线程访问 连续且对齐 的全局内存。一旦满足了凝聚性的要求,设备就会将同一个 warp 的线程对于全局内存的访问合并成最少的内存事务,从而减少读写延迟。凝聚化的要求取决于设备的计算能力:
- 对于计算能力 6.0 及更高的设备,其要求可以简要概括为:一个 warp 内所有线程的并发访问将合并为若干次事务,而事务数量正好等于服务该 warp 全部线程所需的 32Byte 事务的数量。
- 而所谓 32Byte 事务,即是指内存控制器向 DRAM 一次性地、不可分割地读或写入 32Byte 连续内存数据的操作。由此带来了 连续 的读写要求。
- 特别指出,32Byte 事务的起始地址必须是 32 的整数倍(低 5 位为 00000),这是在硬件层面规定的访存最小粒度。由此带来了 对齐 的读写要求。
接下来的几个访问模式样例将使我们对于其对性能方面的影响有更加深入的理解……
凝聚化访存模式
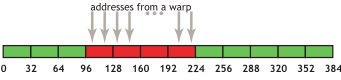
如上图所示,是凝聚化访存的第一种也是最简单的情况:第 k 个线程访问 32Byte 对齐数组中的第 k 个字(int 或者 float)。在上图中,同一个 warp 的 32 个线程各自访问 4 个 Byte,由于边界刚好对齐在内存的 32Byte 处,内存控制器可以将其合并成 4 个 32Byte 事务,这已经是最少的事务数量了。值得一提的是,在过去的较低计算能力的 Cuda 下,如果这 4 个 32Byte 片段内的访问是非顺序的(譬如线程 m 访问第 n 个字,线程 n 访问第 m 个字),此时将无法合并访问事务。 但是对于 6.0 以上的版本,即便线程的访问顺序重排,只要它还是连续且对齐的,就能合并事务。
连续但不对齐的访存模式

上图反映了没有对齐的情况。此时,内存存储器不得不发起 5 个 32Byte 访存事务,才能服务一个 warp 全部线程的访存请求,尽管它已经是连续的了。理由我们之前已经说过了,内存事务必须以 32Byte 作为起始位置,这意味着没有对齐的访存将会占用额外的资源。然而,在实际编程中,我们无需考虑数组的具体大小,我们尽可以相信 arr[0] 总是对齐在 32Byte 的,这是因为使用 CudaMalloc() 能保证至少对齐到 256Byte。但是,我们应该确保 block 的大小是 32 的倍数,以确保相同 warp 的线程总是同时访存。
非连续的访存模式
上图反映了步幅为 2 的非连续访存。这种情况仅具有 50% 的读写效率,因为事务中有一半元素没有被使用,这意味着浪费了带宽。随着跨距的增加,有效带宽会减少。最坏的情况下,可能为 warp 中的 32 个线程加载 32 个 32Byte 片段。因此,无论何时,我们都应该避免非连续的访存。
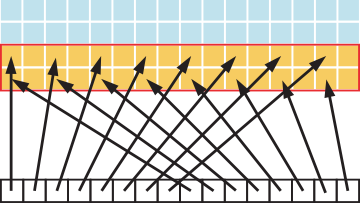
多轮访存下的凝聚化
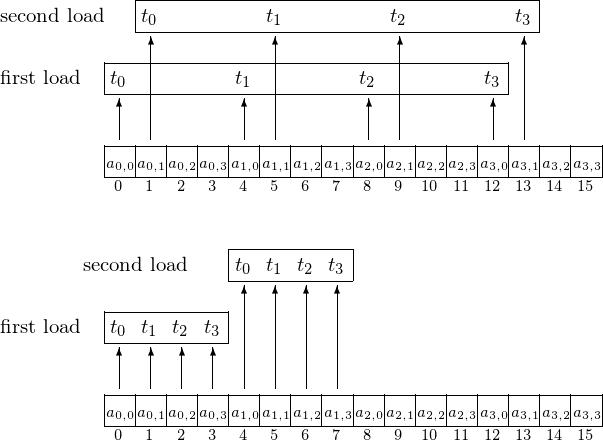
有时,一条线程可能要读取数组中的不同位置,因此可能会产生多轮访存。 上图反映了多轮访存需求下,非凝聚化(上)和凝聚化(下)的访存模式的对比。这提示我们,对于一条线程来说,它应该跨步访问数组中的不同地址,且步幅为线程的总数,而同一个 warp 的线程则应该连续。 因此,在实际开发中,我们通常会有如下的代码实现:
1 | |
共享内存:Memory Bank
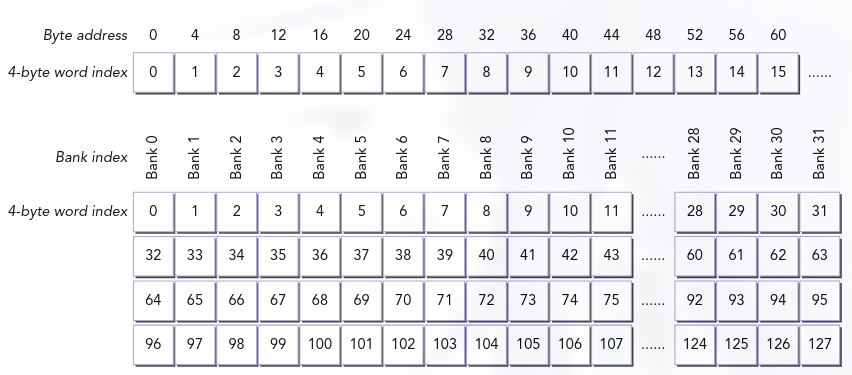
共享内存在片上存储,相比全局内存和本地内存有着更高的带宽和更低的延迟。然而,前提是没有出现 Bank Conflict。在实际架构上,共享内存被划分为 32 个 Bank,这些 Bank 的组织方式是:将连续的 4Byte 字映射到连续的 Bank 中,即第 1 个字映射到 Bank0、第 2 个字映射到 Bank1、……第 32 个字映射到 Bank31、第 33 个字又绕回来映射到 Bank0,以此类推。 如下图。
对于各 Bank 而言,它可以在 1 个时钟周期内执行对于至多 32 位宽的内存的读取和写入操作。 基于这个性质,容易想到:当所有线程访问不同的 Bank 时,只需要 1 个时钟周期,因此是高效的。这种访问也被称作 Bank Conflict Free 的。而如果有多个线程同时访问 Bank 中的不同位置时,就会引发冲突 (Bank Conflict),此时不得不将访存操作序列化,这将超过 1 个时钟周期。此外,还有一种特殊情况,那就是 多个线程访问同一个 Bank 中的相同位置,此时会触发 广播机制,不会引发冲突,因此也是 Bank Conflict Free 的。下图显示了一些跨步访问和广播机制的示例。
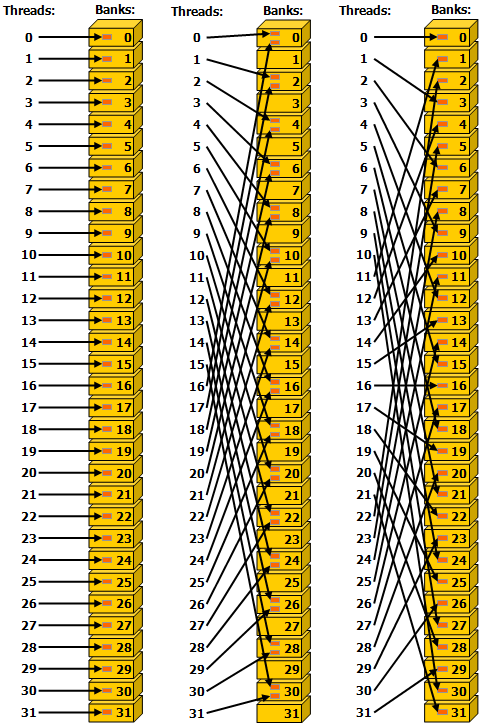
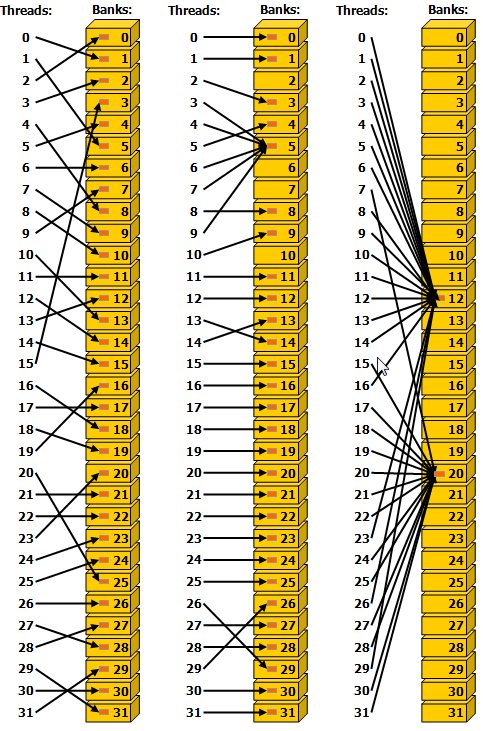
- 左 1:步长为单个 4Byte 字的线性寻址,无冲突。
- 左 2:步长为两个 4Byte 字的线性寻址,冲突。(譬如线程 0 访问位置 0,线程 16 访问位置 32)
- 左 3:步长为三个 4Byte 字的线性寻址,无冲突。
- 右 1:随机排列,无冲突。(与全局内存不同,共享内存可以实现非顺序的高带宽访存)
- 右 2:线程 3、4、5、7 触发广播机制,无冲突。
- 右 3:多个线程访问相同 Bank 的相同位置,触发广播机制,无冲突。
将共享内存用于矩阵乘法的优化 C=AB
由于共享内存有着比全局内存更高的带宽和更低的延迟,且没有凝聚化访存的要求,通常可以把它当作片外内存到片内的“中转站”。当块中的多个线程需要使用全局内存中的相同数据时,可借助共享内存实现只读全局内存中的数据一次。 此外,共享内存还支持线程间的协作,从而避免未合并的全局内存访问。 具体流程是:先从全局内存中以合并的模式加载和存储数据,然后在共享内存中重新排序。
我们通过一个简单的矩阵乘法示例 C=AB 来说明共享内存的使用,其中 A 维数为 $M \times w$,B 维数为 $w \times N$,C 维数为 $M \times N$。为了简化内核,$M$ 和 $N$ 均为 32 的倍数,$w$ 也等于 32,即 1 个 warp 的大小。问题的自然分解是使用大小为 $w \times w$ 的线程块和子矩阵,如下图所示。启动一个由 $\frac{M}{w}\times\frac{N}{w}$ 个块组成的网格,其中每个线程块计算 $w \times w$ 区域的子矩阵。
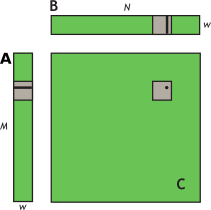
1 | |
我们分析上述代码的性能,考虑一个 warp 是如何在 for 循环里访问数组 a 和数组 b 的。容易看出,每个 warp 计算子矩阵的一行,该行取决于矩阵 A 的一行和矩阵 B 的一块,如下图所示。
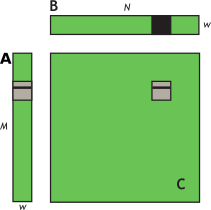
在 for 循环的每次迭代中,一个 warp 的线程将会读取矩阵 B 的块内的一行,即 b[i * N + col],这一访存是凝聚化的。然而,同一个 warp 的线程会在同一时刻同时访问矩阵 A 的行的同一个元素,即 a[row * w + i]。尽管这只需要 1 个内存事务,但是带宽仍然被浪费了,因为这个 32Byte 的内存事务只有 4Byte 被利用了。理想状态下,我们会希望只读取 A 的行上的元素一次,之后重复利用。如下所示。
1 | |
在上述代码中,矩阵 A 的块中的每个元素仅从全局内存中读取 1 次,并且是以合并的形式 a[row * w + threadIdx.x] 写入共享内存。此后,在每次迭代中,同一 warp 的线程同时访问共享内存中相同位置的元素 sa[threadIdx.y][i],触发了共享内存的广播机制。这里使用 __syncwarp() 以确保矩阵 A 的一行被完全读入。 如果我们把视角从 warp 扩大到 block,会发现同一 block 的 warp 会重复地读取矩阵 B 的相同列,因此我们可以考虑将 B 也读入共享内存,此时需要使用 __syncthreads(),如下。
1 | |
在这个例子中,线程不但会利用相同 warp 中的其他线程读入的数据 sa,还会利用其他 warp 中有着相同 threadIdx.x 的线程读入的数据 sb。上述的两个例子的性能提升并非源于两种情况下的合并改进,而是源于避免了全局内存的冗余传输。在 Tesla V100 上测试表明,使用共享内存转储 A 和 B 的子矩阵可使实际带宽从 119.9 GB/秒 提升至 195.5 GB/秒。
Register:寄存器压力
通常来说,对寄存器的访存所带来的时间开销几乎可以忽略不计。 然而,写后读依赖 (RAW, Read-after-Write Dependencies) 和寄存器的 Bank Conflict 可能导致额外的延迟。不过,目前编译器与线程调度器会已经能够以最优方式调度指令以避免寄存器 Bank Conflict,并且实际编程过程中也很少会直接操控寄存器的行为。总而言之,在寄存器方面的访存优化,主要考虑 避免寄存器压力。
譬如,假设一份完整的 SM 一共有 65535 个寄存器,可以存储 64K 个浮点数,而每块 SM 可以搭载至多 1024 条线程。那么每个线程不应开辟多于 64 个的浮点数。换言之,在核函数内进行 float arr[64] 等的操作是不被建议的。
如果一个线程使用的寄存器过多,则会严重限制 SM 上能够同时驻留的线程数量,从而降低占用率。此外,当编译器发现一个线程所需的寄存器数量超过其所能分配的上限,它会将一部分自动变量“溢出”到所谓的 本地内存 中。本地内存位于片外的 DRAM,实质上是全局内存的一部分,对它的访问是严重低效的。
到此,我们已经掌握了 CUDA 访存优化相关的全部基础知识了!鼓掌👏👏👏