从集合论到位运算,常见位运算技巧分类总结!
以集合论为指导,利用位运算实现复杂操作!
本篇博客受到 灵茶山艾府 的启发,并结合了自己在实践过程中的经验。经实践,在集合论的指导下使用位运算能够大大地提高对某些问题的求解效率和质量。 总的来说,使用位运算可以极大减少内存占用,而同时将时间复杂度降低至与使用复杂的数据结构相当。
从集合到位运算
在高中,我们学了 集合论 (set theory) 的相关知识。例如,包含若干整数的集合 $S=\{0,2,3\}$。在编程中,通常用哈希表(hash table)表示集合,例如 Java 中的 HashSet。在集合论中,有交集 $\cap$、并集 $\cup$、包含于 $\subseteq$ 等等概念。如果编程实现 “求两个哈希表的交集”,需要一个一个地遍历哈希表中的元素,时间复杂度是 O(N)。那么,有没有效率更高的做法呢?有的,兄弟。有的。
集合可以用二进制表示,二进制从低到高第 $i$ 位为 1 表示 $i$ 在集合中,为 0 表示 $i$ 不在集合中。 例如集合 $\{0,2,3\}$ 可以用二进制数 $1101_{(2)}$ 表示;反过来,二进制数 $1101_{(2)}$ 就对应着集合 $\{0,2,3\}$。也即,包含非负整数的集合 $S$ 可以用如下方式“压缩”成一个数字:$$f(S)=\underset{i\in{S}}{\sum}2^i$$ 例如集合 $\{0,2,3\}$ 可以被压缩成 $2^0+2^2+2^3=13$,也就是二进制数$1101_{(2)}$。由此,我们可以利用位运算高效地做一些和集合有关的运算。 按照常见的应用场景,可以分为以下四类:集合与集合、集合与元素、遍历集合、枚举集合。
集合与集合
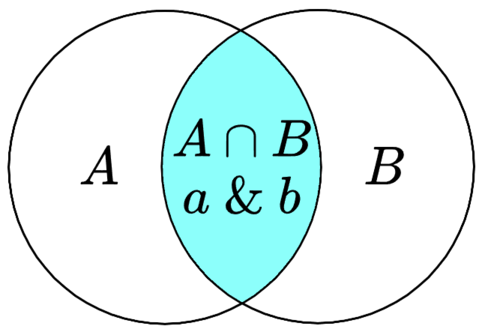
其中 $\&$ 表示按位与,$∣$ 表示按位或,$\oplus$ 表示按位异或,$\sim$ 表示按位取反。两个集合的 “对称差” 是只属于其中一个集合,而不属于另一个集合的元素组成的集合,也就是不在交集中的元素组成的集合。
| 术语 | 集合运算 | 位运算 | 集合示例 | 位运算示例 |
|---|---|---|---|---|
| 交集 | $A \cap B$ | $a \& b$ | $\{0,2,3\} \cap \{0,1,2\} = \{0,2\}$ | $1101 \& 0111 = 0101$ |
| 并集 | $A \cup B$ | $a \mid b$ | $\{0,2,3\} \cup \{0,1,2\} = \{0,1,2,3\}$ | $1101 \mid 0111 = 1111$ |
| 对称差 | $A \bigtriangleup B$ | $a \oplus b$ | $\{0,2,3\} \bigtriangleup \{0,1,2\} = \{1,3\}$ | $1101 \oplus 0111 = 1010$ |
| 差 | $A \setminus B$ | $a \& \sim b$ | $\{0,2,3\} \setminus \{1,2\} = \{0,3\}$ | $1101 \& 1001 = 1001$ |
| 子集差 | $A \setminus B$ $(B \subseteq A)$ | $a \oplus b$ | $\{0,2,3\} \setminus \{0,2\} = \{3\}$ | $1101 \oplus 0101 = 1000$ |
| 包含于 | $A \subseteq B$ | $a \& b = a$ $a \mid b = b$ |
$\{0,2\} \subseteq \{0,2,3\}$ | $0101 \& 1101 = 0101$ $0101 \mid 1101 = 1101$ |
集合与元素
通常会用到位移运算。其中 << 表示左移,>> 表示右移。左移 $i$ 位相当于乘以 $2^i$,右移 $i$ 位相当于除以 $2^i$。我们通常会利用位移运算进行一些元素与集合间的操作。
| 术语 | 集合运算 | 位运算 | 集合示例 | 位运算示例 |
|---|---|---|---|---|
| 空集 | $\emptyset$ | $0$ | $0$ | |
| 单元素集合 | $\{i\}$ | $1 \ll i$ | $\{2\}$ | $1 \ll 2$ |
| 全集 | $U = \{0,1,2,\dots,n-1\}$ | $(1 \ll n) - 1$ | $\{0,1,2,3\}$ | $(1 \ll 4) - 1 = 15$ |
| 补集 | $\complement_U S = U \setminus S$ | $((1 \ll n) - 1) \oplus s$ | $U = \{0,1,2,3\}$ $\complement_U \{1,2\} = \{0,3\}$ |
$1111 \oplus 0110 = 1001$ |
| 属于 | $i \in S$ | $(s \gg i) \& 1 = 1$ | $2 \in \{0,2,3\}$ | $(1101 \gg 2) \& 1 = 1$ |
| 不属于 | $i \notin S$ | $(s \gg i) \& 1 = 0$ | $1 \notin \{0,2,3\}$ | $(1101 \gg 1) \& 1 = 0$ |
| 添加元素 | $S \cup \{i\}$ | $s \mid (1 \ll i)$ | $\{0,3\} \cup \{2\}$ | $1001 \mid (1 \ll 2) = 1101$ |
| 删除元素 | $S \setminus \{i\}$ | $s \& \sim (1 \ll i)$ | $\{0,2,3\} \setminus \{2\}$ | $1101 \& \sim (1 \ll 2) = 1001$ |
| 删除在集合中元素 | $S \setminus \{i\}, i \in S$ | $s \oplus (1 \ll i)$ | $\{0,2,3\} \setminus \{2\}$ | $1101 \oplus (1 \ll 2) = 1001$ |
| 删除最小元素 | $s \& (s - 1)$ | $1100 \& 1011 = 1000$ |
此外,编程语言提供了一些和二进制有关的库函数,例如:
- 计算二进制中的 1 的个数,也就是集合大小;
- 计算二进制长度,减一后得到集合最大元素;
- 计算二进制尾零个数,也就是集合最小元素。
调用这些函数的时间复杂度都是 O(1)。
| 术语 | Python | Java | C++ | Go |
|---|---|---|---|---|
| 集合大小 | s.bit_count() |
Integer.bitCount(s) |
__builtin_popcount(s) |
bits.OnesCount(s) |
| 二进制长度 | s.bit_length() |
32-Integer.numberOfLeadingZeros(s) |
__lg(s)+1 |
bits.Len(s) |
| 集合最大元素 | s.bit_length()-1 |
31-Integer.numberOfLeadingZeros(s) |
__lg(s) |
bits.Len(s)-1 |
| 集合最小元素 | (s&-s).bit_length()-1 |
Integer.numberOfTrailingZeros(s) |
__builtin_ctz(s) |
bits.TrailingZeros(s) |
请特别注意 s=0 的情况。对于 C++ 来说,__lg(0) 和 __builtin_ctz(0) 是未定义行为。其他语言请查阅 API 文档。此外,对于 C++ 的 long long,需使用相应的 __builtin_popcountll 等函数,即函数名后缀添加 ll(两个小写字母 L)。__lg 支持 long long。
除上述所举操作外,还有获取集合的只包含最小元素的子集的操作。 即二进制最低 1 及其后面的 0,也叫 lsb (最低有效位),可以用 s&-s 算出,它用到了二进制中补码的定义。补码就是按位取反后加 1,举例说明:$1011\&0101=0001$。
遍历集合
设元素范围从 $0$ 到 $n−1$,枚举范围中的元素 $i$,判断 $i$ 是否在集合 $s$ 中。
1 | |
也可以直接遍历集合 $s$ 中的元素:不断地计算集合最小元素、去掉最小元素,直到集合为空。
1 | |
枚举集合
枚举所有集合
设元素范围从 $1$ 到 $n-1$,从空集 $\emptyset$ 枚举到全集 $U$。
1 | |
枚举非空子集
设集合为 $s$,从大到小枚举 $s$ 的所有非空子集 $sub$。
1 | |
枚举含空子集
从大到小枚举 $s$ 的所有子集 $sub$,包括空集 $0$。
1 | |
Gophers’ Hack
枚举全集 $U=\{0,1,2\cdots,n-1\}$ 的所有大小恰好为 $k$ 的子集,总的子集数目应当为组合数 $C_{n}^{k}$。Gophers’ Hack 可以保证时间复杂度为最小的 $O(C_{n}^{k})$,绝不遍历多余的元素。
1 | |
枚举超集
如果 $T$ 是 $S$ 的子集,那么称 $S$ 是 $T$ 的超集(superset)。枚举超集的原理和上文枚举子集是类似的,这里通过或运算保证枚举的集合 $S$ 一定包含集合 $T$ 中的所有元素。枚举 $S$,满足 $S$ 是 $T$ 的超集,也是全集 $U=\{0,1,2,\cdots,n−1\}$ 的子集。
1 | |
来看如下例题
世界杯赢家
题目描述
假设有 n 场比赛,每场比赛均分出胜负,没有平局。请找出没有输掉任何比赛,且至少参加了一场比赛的全部国家,并按国家编号递增输出;若不存在这样的国家,输出空列表。
关于输入
正整数 n,表示比赛场数。包含 n 个元组的列表 arr。其中每个元组由两个元素组成,第一个是获胜的国家编号,第二个是失败的国家编号。比赛场数和国家编号均介于 [1, 100000]。
关于输出
列表,包含没有输掉任何比赛的全部国家编号,但不包括那些没有参与过任何一场比赛的国家。列表的最大长度显然为 1000000。
常规解法
1 | |
使用位运算的解法
1 | |
| 算法 | 时间复杂度 | 空间复杂度 | 关键点 |
|---|---|---|---|
| 常规解法 | $O(N + K \log K)$ | $O(U)$ | 集合与排序主导时间,空间取决于国家数量 |
| 位运算解法 | $O(N + K)$ | $O(M)$ | 位运算和遍历主导时间,空间取决于编号大小 |
- 常规解法遍历所有比赛后,求差集并排序,其时间复杂度为 $O(N + W + K \log K)$。$N$ 为
arr长度;$W$ 为winners集合大小、可忽略不记;$K$ 为结果集合的大小。常规解法用到了 2 个集合,集合的大小取决于国家的数量 $U$。 - 位运算解法用大整数代替集合,用
|=操作代替集合的add()操作,结果无需排序,直接遍历输出,其时间复杂度为 $O(N + K)$。它使用两个大整数来存储winners和losers。假设国家的最大编号为 $M$,那么它需要 $2M$ 位空间。 - 常规解法适合国家编号范围较大但实际参与国家较少($U << M$)的情况,位运算解法适合国家编号范围较小(如 $M \le 64$)且结果数量 $K$ 较大的场景,避免排序开销。