关于 Transformer 架构在 CV 领域的应用🧐
关于 Transformer 架构在 CV 领域的应用
本研读报告旨在探究 Transformer 在 CV 领域的应用状况,包括如下两篇论文:
- 论文1:An Image Is Worth 16x16 Words: Transformers For Image Recognition At Scale.
- 论文2:Hard Patches Mining for Masked Image Modeling.
第一篇是将 Transformer 用于 CV 领域的开山之作,它的出现也引爆了后续许多的相关研究;
而第二篇着眼于 MIM 预训练任务,提出了一种指导模型学习,而非人工预设预训练任务的新方法。
前言
注意力机制(Attention Mechanisms)最开始被用于处理翻译任务中的对齐问题,自谷歌的 Transformer 问世后便愈发在 NLP 领域大显神威(BERT;
RoBERTa; GPT-3; T5; LLaMA)。
同时,在图像领域,也逐渐有人沿用 Transformer 中 Encoder-Decoder 的思路,将注意力机制用于图片分类、目标检测、语义分割等任务中。而随着与 Transformer 结构上高度相仿的 Vit 的出现,一种简单有效地应用 Transformer 的方法出现在 CV 领域。
受此激励,愈来愈多的学者致力于构建与 Vit 相适应的自监督学习方法(Vit-SLP; DINO; MicroV3)。
其中,受 MLM(Masked Language Model)启发而诞生的各种 MIM(Masked Image Model)方法(BEiT; MAE; SimMIM; MaskFeat)取得了较可观的成果。
然而,传统 MIM 方法依赖于掩码策略的制定,难以确保能够充分利用模型的学习能力。为此,开始有人提出让模型自主挖掘难学习掩码。
ViT:奠定 Transformer 用于 CV 领域的基础
ViT 背景及动机
Transformer 早在 2017 年便已提出,但直到 2020 年 ViT 出现,它才真正被直接用于图像领域。在此之前,虽不乏各种将 Transformer 用于视觉任务的方法,但很少有能真正突破 CNN 架构的可扩展模型(Scalable Model)出现。Transformer 在 CV 领域的进展如此缓慢:
- 一方面是受限于算力,与计算文本相比,计算图片显然需要更多更强的算力;
- 另一方面是因为与 CNN 相比,Transformer 舍弃了包括
局部性(Locality)和平移不变性(Translation Equivariance)在内的先验归纳偏置(Prior Inductive Bias),使模型的训练和推理极难。
在 Cordonnier 等人 的基础上,Vit 扩大了切割图片的尺度从而使之能够适应高分辨率的图片。大量的实验证明,Vit 在大规模训练数据的加持下能够自行习得归纳偏置,在下游任务获得比 CNN 更好的迁移效果。
ViT 思路方法
针对二维图像,Vit 将图像 $x \in \mathbb{R}^{H \times W \times C}$ 重塑为扁平化的图块序列 $x_p \in \mathbb{R}^{N \times (P^2 \cdot C)}$,其中:
- $(H, W)$ 是原始图像的分辨率;
- $C$ 是通道数;
- $(P, P)$ 是每个图块的分辨率;
- $N = HW/P^2$ 是得到的块数,也作为 Transformer 的有效输入序列长度。
Transformer 在其所有层中使用固定的隐藏层维度 $D$,因此需要将每个图块扁平化并通过可训练的线性投影映射到 $D$ 维。这一过程的输出即称作“块嵌入”(Patch Embeddings)。与 BERT 类似,Vit 在嵌入块序列前添加了一个可学习的嵌入 $z_0^0 = x_\mathsf{class}$,其最终输出状态 $z_L^0$ 用作图像的总体表示 $y$。在预训练阶段,对 $y$ 施加具有单隐藏层的 MLP 作为分类头;而在微调时,分类头通过单个线性层实现。
为引入适量的位置信息以弥补 Transformer 对于图归纳偏置的损失,Vit 在原有的块嵌入上添加上位置嵌入(Position Embedding)从而得到最终输入 Transformer 的嵌入序列。上述过程可以表示为公式:
$$z_0 = [x_\mathsf{class}; x_p^1E; x_p^1E; \cdots; x_p^NE] + E_{pos},\qquad E \in \mathbb{R}^{P^2 \cdot C \times D}, E_{pos} \in \mathbb{R}^{(N+1) \times D}$$
ViT 模型架构
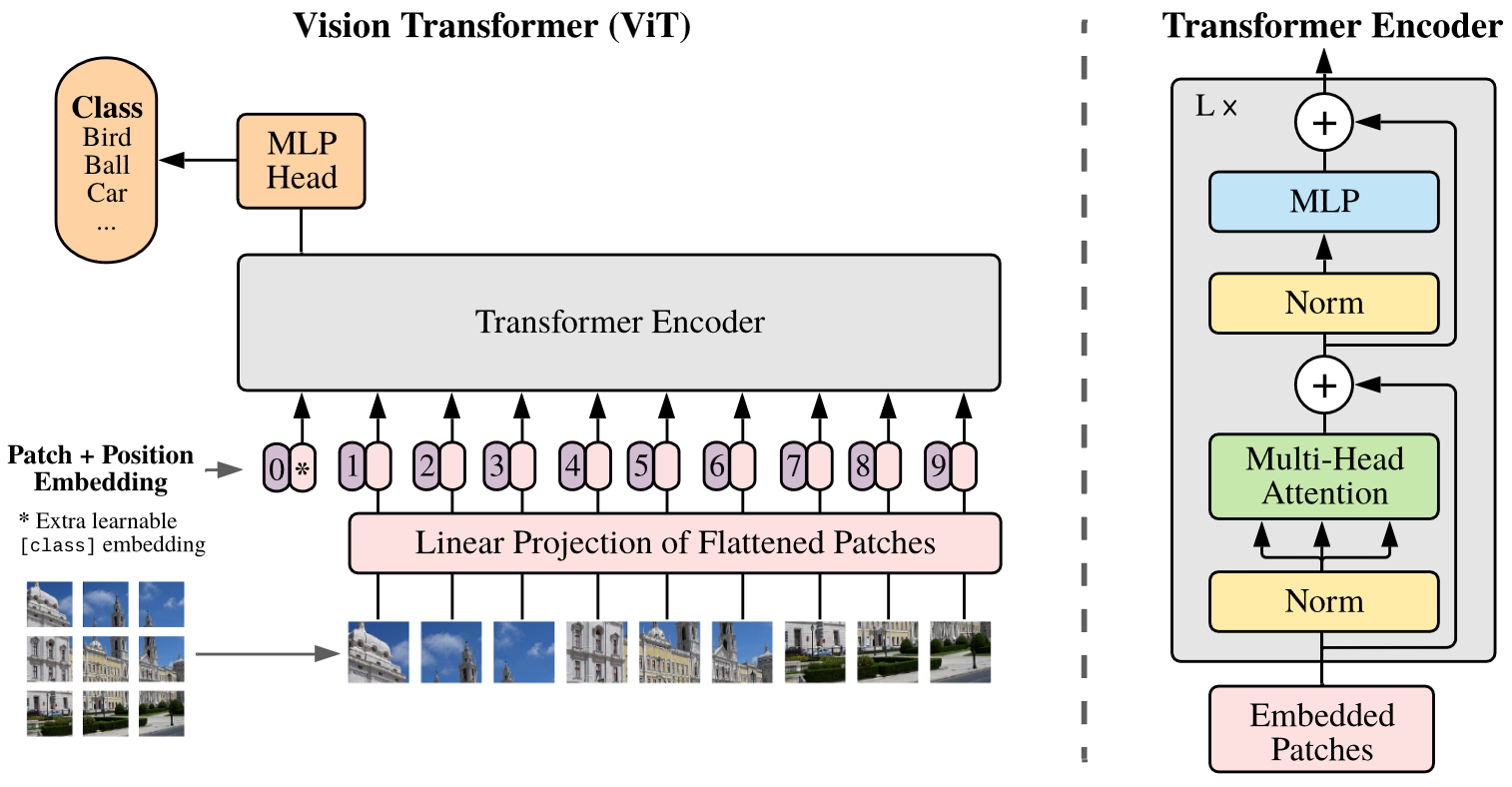
经过序列化和块嵌入的序列被送入 Transformer 的 Encoder 之中,后续操作与原始 Transformer 的 Encoder 完全相同:
- Encoder 由顺序连接的多个层组成,每个层都是前后连接的一个多头自注意力模块和一个 MLP 模块,且每个模块的输出都使用了残差连接,并进行层归一化。
- 其中,MLP 包含两层,且使用 GELU 作为激活函数。
- Encoder 内不做任何掩码,以便模型注意到全局的信息。
注意到,Vit 引入了非常有限的图像归纳偏置,且初始化时的位置嵌入不携带任何有关图块的二维位置信息,因此所有图块间的关系都必须从头开始学习。
通常,以比预训练更高的分辨率进行微调是有益的。在微调阶段,对于具有更高分辨率的图像,Vit 保持图块大小与预训练时一致,从而接受一个更长的有效序列。在不超过内存的情况下,Transformer 可以处理任意长度的序列,但是这样预训练的位置嵌入将不再有意义。为此,Vit 根据其在原始图像中的位置对预训练的位置嵌入进行二维插值,从而扩充位置嵌入的长度,这一做法被证明是有效的。
在论文中,作者基于 BERT 使用过的配置来配置 Vit 的参数量。如下表所示:Base 和 Large 模型直接采用 BERT 的模型结构。此外,还增加了更大的 Huge 模型,具有更深的层数、更高的隐藏层维度和更多的自注意力头等等。在阐述实验结果的部分,原论文使用简短的符号来表示模型大小和输入块大小:例如,ViT-L/16 表示输入块大小为 16x16 的 Large 变体。由于 Transformer 的序列长度与块大小的平方成反比,因此具有较小块大小的模型在计算上更昂贵。
| Model | Layers | Hidden size $D$ | MLP size | Heads | Params |
|---|---|---|---|---|---|
| ViT-Base | 12 | 768 | 3072 | 12 | 86M |
| ViT-Large | 24 | 1024 | 4096 | 16 | 307M |
| ViT-Huge | 32 | 1280 | 5120 | 16 | 632M |
ViT 实验及结果
数据集的选取上,预训练阶段使用了 ImageNet-1K(1.3M)、ImageNet-21K(14M) 和 JFT-18K(303M) 三种数据集,用于探究模型的可扩展性。同时参考 BiT,删除预训练数据集中和下游任务测试集中重复的数据。而下游数据集包括 ImageNet(原始验证标签)、ImageNet(清理后的真实标签)、CIFAR-10/100、Oxford-IIIT Pets、Oxford Flowres-102、VTAB(19 tasks)。而在 Baseline 的选取上,除了上述提到的 Vit 的三个变体,还选取了 ResNet 作为 CNN 的 baseline,以及 Vit 同 ResNet50 的结合体作为混合模型的 baseline。
所有模型(包括 Baseline )的预训练 batchsize 设为 4096,优化器选用 Adam($\beta_1=0.9$,$\beta_2=0.999$ );微调阶段 batchsize 设为 512,优化器使用带动量的 SGD。学习率使用线性 warmup + decay 的策略,衰减率为 0.1。在基学习率的选取上采用了网格搜索。原论文的实验结果主要关注三方面:
- Vit 与其他模型表现效果的比较;
- Vit 对预训练数据规模大小的要求;
- Vit 的预训练成本。
在与其他模型表现效果的比较上,如下表所示:可以看到在 JFT 数据集上预训练的 ViT 模型,迁移到下游任务后,其表现要好于基于 ResNet 的 BiT 和基于 EfficientNet 的 Noisy Student。
| Ours-JFT (ViT-H/14) | Ours-JFT (ViT-L/16) | Ours-I21k (ViT-L/16) | BiT-L (ResNet152x4) | Noisy Student (EfficientNet-L2) | |
|---|---|---|---|---|---|
| ImageNet | 88.55 ± 0.04 | 87.76 ± 0.03 | 85.30 ± 0.02 | 87.54 ± 0.02 | 88.4/88.5 |
| ImageNet ReaL | 90.72 ± 0.05 | 90.54 ± 0.03 | 88.62 ± 0.05 | 90.54 | 90.55 |
| CIFAR-10 | 99.50 ± 0.06 | 99.42 ± 0.03 | 99.15 ± 0.03 | 99.37 ± 0.06 | − |
| CIFAR-100 | 94.55 ± 0.04 | 93.90 ± 0.05 | 93.25 ± 0.05 | 93.51 ± 0.08 | − |
| Oxford-IIIT Pets | 97.56 ± 0.03 | 97.32 ± 0.11 | 94.67 ± 0.15 | 96.62 ± 0.23 | − |
| Oxford Flowers | 99.68 ± 0.02 | 99.74 ± 0.00 | 99.61 ± 0.02 | 99.63 ± 0.03 | − |
| VTAB (19 tasks) | 77.63 ± 0.23 | 76.28 ± 0.46 | 72.72 ± 0.21 | 76.29 ± 1.70 | − |
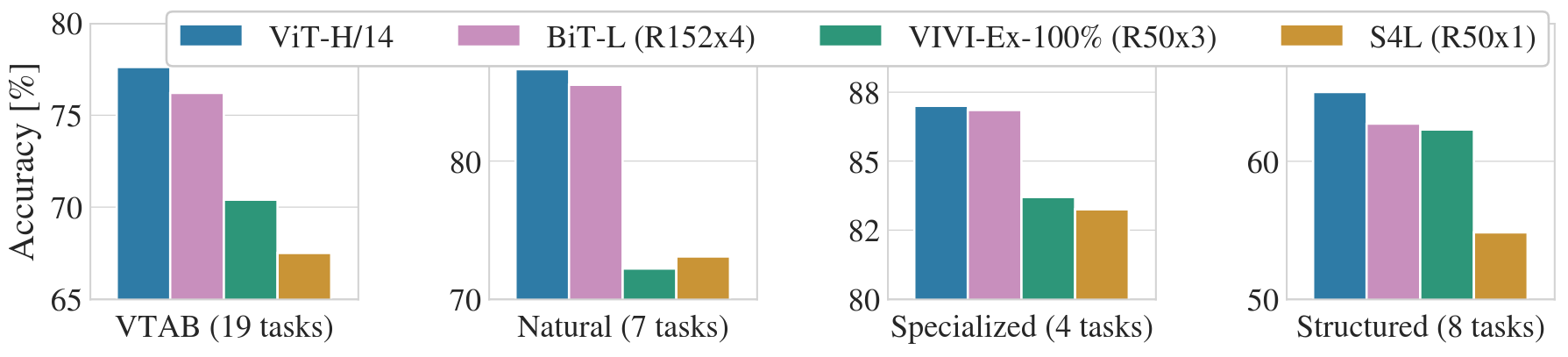
针对 VTAB 细分任务,如图所示:当在很大的数据集上预训练时,ViT 性能超越 CNN。
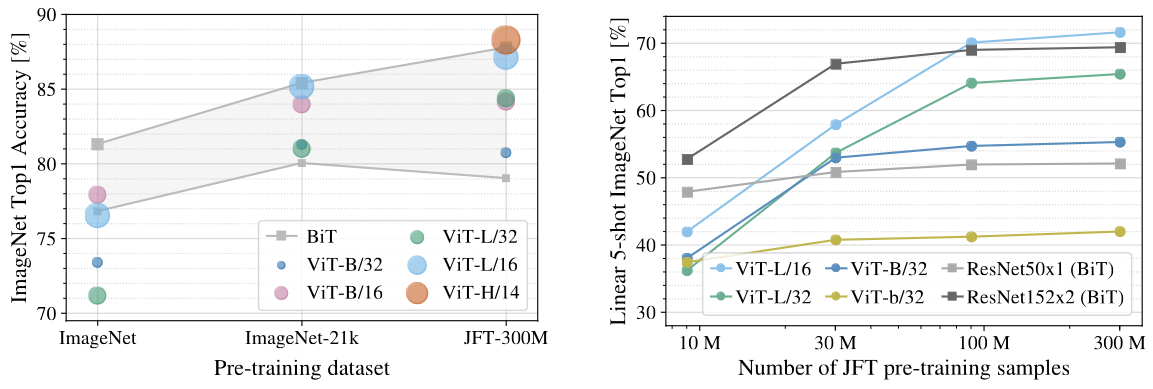
而在不同预训练数据规模大小对模型性能的影响方面,如图所示,可以发现:首先,Vit 是具有可扩展性的模型,预训练数据规模越大,则其在下游任务的表现越好;其次,当在小数据集上预训练时,ViT 微调后的效果远远比不上 ResNet,当在很大的数据集上预训练时,ViT 的效果要更好。
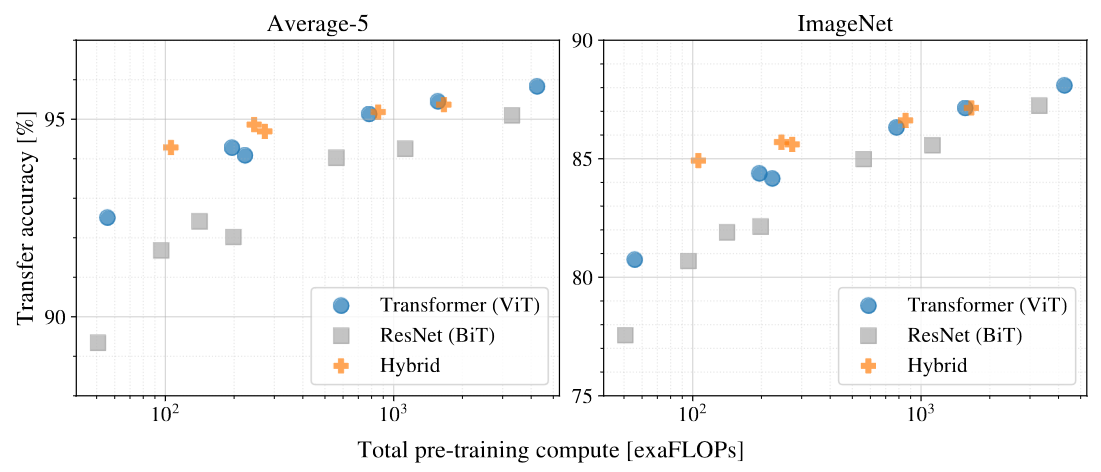
最后,在预训练计算成本的比较方面,如图所示:实验证明,ViT 的预训练比 ResNet 要更便宜,即在相同的预训练计算复杂度下,ViT 的效果要比 ResNet 更好。可以看到,当模型较小时,混合模型的表现要更好,但是随着模型的增大,ViT 的表现超过了混合模型。
总之,Vit 提出将 Transformer 用于 CV 领域的有效方法,并通过实验证明其在准确率、可扩展性和预训练成本等方面的优越性。
HPM:针对 MIM 的预训练任务生成方法
背景及动机
Vit 证明将图片分块化成扁平序列的做法是有效的,这使得人们确信:在 NLP 领域使用的模型、思想和方法等也同样能用于 CV 领域。受诸如 BERT 等 MLM 的启发,愈来愈多人开始关注如何将掩码机制应用于 CV 领域,从而催生出 MIM 这一成熟流派。然而,与 NLP 不同,计算机视觉中冗余的空间信息(包括局部性和平移不变性)使得模型从掩码重构原图是极容易的,因而 MIM 的表现效果常严重依赖于人工选取的掩码策略。为解决这一问题,HPM(Hard Patch Mining)试图训练一个“老师模型”(teacher),让其习得哪些图块是难重构的,然后让这个“老师模型”来给“学生模型”(student)派发预训练任务,如图所示。
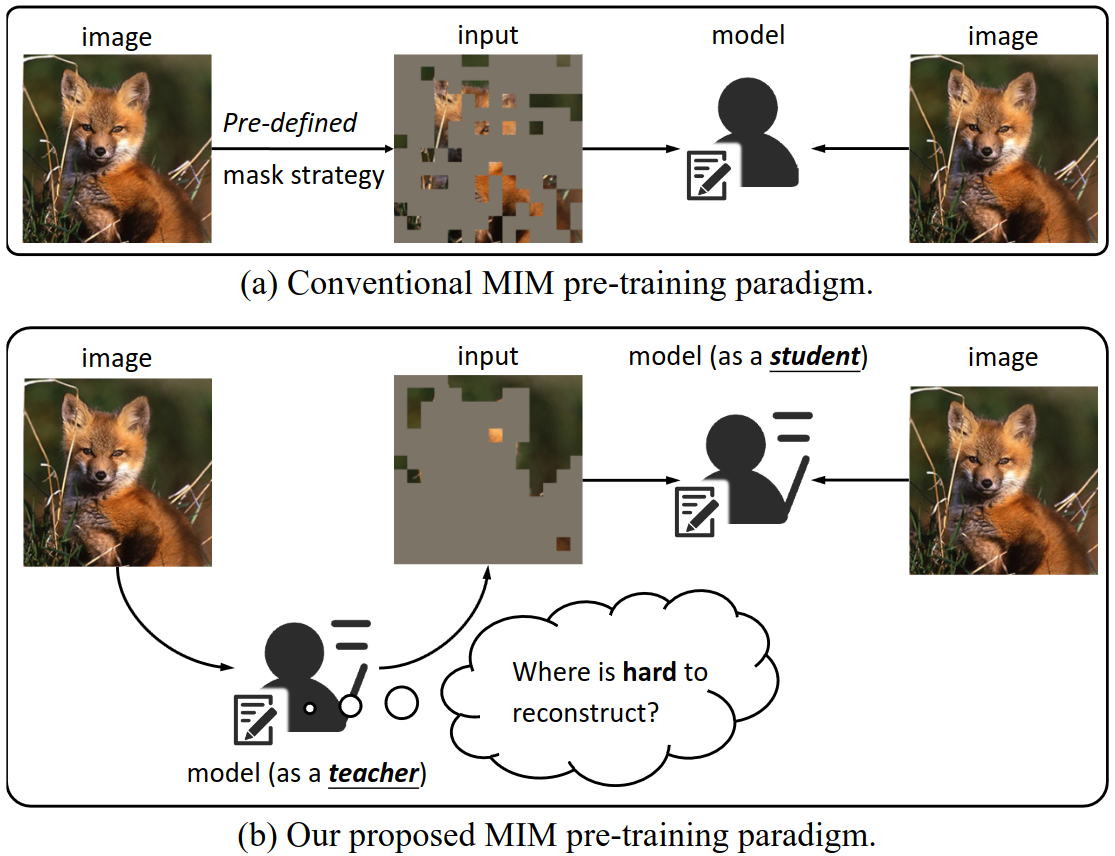
HPM 思路方法
很自然地,难重构的图块通常有较大的重构损失。基于此,他们为 teacher 引入名为损失预测头(Loss Predictor)的解码器来逐块预测损失,并根据输出大小决定要掩码的图块。考虑到重构损失的确切值是连续不间断的值,为防止预测头过分关注重构损失的具体数值而忽略图块间的相对关系,他们设计了一种基于 BCE-Loss(Binary Cross Entropy Loss) 的相对损失作为优化目标。
在设计中,将 teacher 定义为($f_{\theta_t}$,$d_{\phi_t}$,$d_{\psi_t}$),将 student 定义为($f_{\theta_s}$,$d_{\phi_s}$,$d_{\psi_s}$),二者具有相同的结构(enc+2dec)。$f_{\theta}(\cdot)$,$d_{\phi}(\cdot)$ 和 $d_{\psi}(\cdot)$ 分别表示编码器、图像重构头、损失预测头,下标 $t$ 和 $s$ 分别表示老师(teacher)和学生(student)。为了得到一致的预测结果,在训练阶段,对 teacher 的参数实施动量更新:
$$\theta_t \leftarrow m \theta_t + (1 - m) \theta_s$$
HPM 模型架构
每次迭代中,输入图像 $I \in \mathbb{R}^{H \times W \times C}$ 被重塑成图块序列 $x \in \mathbb{R}^{N \times (P^2C)}$(同 Vit)。之后,$x$ 输入 teacher 得到每个图块对应的预测重构损失 $\mathcal{\hat{L^t}} = d_{\psi_t}(f_{\theta_t}(x))$,与之对应的是真实重构损失 $\mathcal{L_{rec}}$。再然后,基于预测损失 $\mathcal{\hat{L}^t}$ 和 teacher 当前的训练 epoch,采用 Easy-to-Hard 的策略,将能得到掩码序列 $M \in {0, 1}^N$。最后,计算预测重构损失的损失 $\mathcal{L_{pred}}$,student 就基于 $\mathcal{L_{rec}}$ 和 $\mathcal{L_{pred}}$ 两个损失的和进行反向传播,更新参数,并将其参数动量更新至 teacher。其中,真实的重构损失 $\mathcal{L_{rec}}$ 可表示为:
$$\mathcal{L_{rec}} = \mathcal{M}(d_{\theta_s}(f_{\theta_s}(x \odot M)), \mathcal{T}(x \odot (1 - M)))$$
它衡量掩盖后的图像经过 student 编解码后的还原程度。$M \in {0, 1}^N$ 是掩码序列,从而 $x \odot M$ 表示可见图块。$\mathcal{T}$ 是理想函数,表示将图像完全复原的操作。$\mathcal{M}$ 是衡量两副图片相似性的 measuremant,常用的有 $l_2$-distance,smooth $l_1$-distance,知识蒸馏和交错熵等。
可以看出,重构损失的计算依赖于掩码序列 $M$ 的给定。那么在训练的早期阶段(epoch 尚小),teacher 还无法给出可信的掩码序列,此时只能进行随机掩码。而随着训练轮次的增多,应当减少随机掩盖的部分,增加 teacher 预测的掩码,这一策略被称作 Easy-to-Hard,用于解决重构损失的冷启动问题。
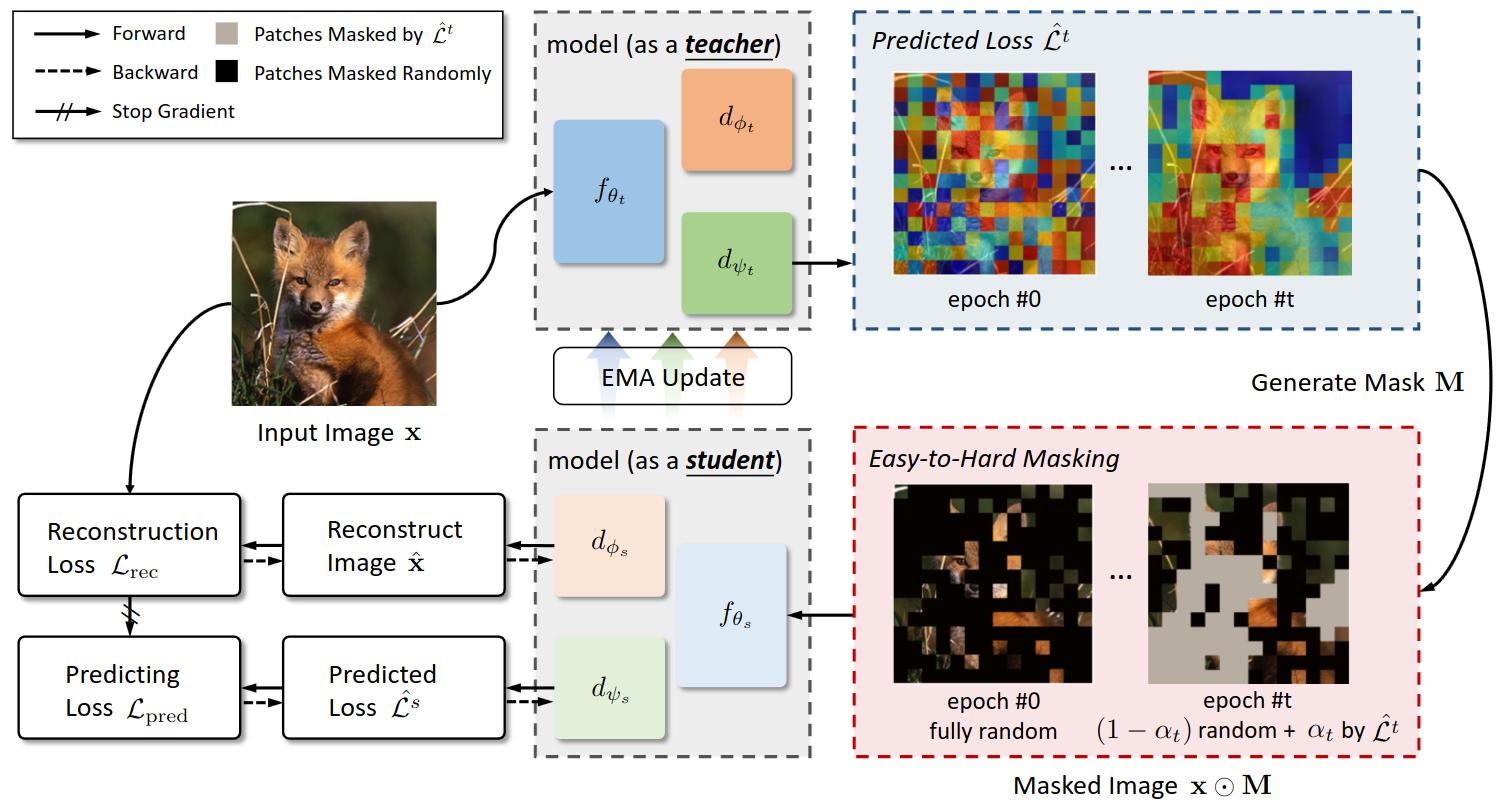
另一方面,在计算预测重构损失的损失 $\mathcal{L_{pred}}$ 上,HPM 并不关注真实损失的具体数值,而更加关注各图块损失的大小关系。若预测损失的大小排序和真实损失的大小排序接近,则 $\mathcal{L_{pred}}$ 小,反之则大。论文中对 $\mathcal{L_{pred}}$ 的公式定义如下:
$$
\begin{aligned}
\mathcal{L_{pred}} = &- \overset{N}{\underset{i=1}{\sum}} \underset{j\ne i}{\underset{j=1}{\sum}} \mathbb{1}_{ij}^{+} \mathsf{log} (\sigma(\mathcal{\hat{L^s_i}} - \mathcal{\hat{L^s_j}}))\\
&- \overset{N}{\underset{i=1}{\sum}} \underset{j\ne i}{\underset{j=1}{\sum}} \mathbb{1}_{ij}^{-} \mathsf{log} (1 - \sigma(\mathcal{\hat{L^s_i}} - \mathcal{\hat{L^s_j}}))
\end{aligned}
$$
- 它表示预测损失与真实损失在排序上的接近程度;
- $\mathbb{1}_{ij}^{+}$ 表示图块 $i$ 的真损失大于图块 $j$ 的真损失的情况;
- $\mathsf{log}$ 括号内是图块 $i$ 的预测损失大于图块 $j$ 的预测损失的概率;
- $\mathbb{1}_{ij}^{-}$ 与之恰好相反。$\sigma$ 是 Sigmoid 函数。
在整个训练过程中,$\mathcal{L_{pred}}$ 与 $\mathcal{L_{rec}}$ 两者不断此消彼长,持续给模型抛出难重构的图块,从而使模型更加关注难解决的部分。
HPM 实验及结果
实验所用的数据集是 ImageNet-1K,以 Vit-B/16 为 backbone,以在 ImageNet-1K 上进行 200 轮预训练的 MAE 作为 baseline。为了比较 HPM 与 baseline,将二者在图片分类、目标检测、语义分割三种下游任务分别进行微调,从而获得三组对照数据。在消融实验部分,主要针对重构目标、掩码策略和预测损失的计算方式进行。
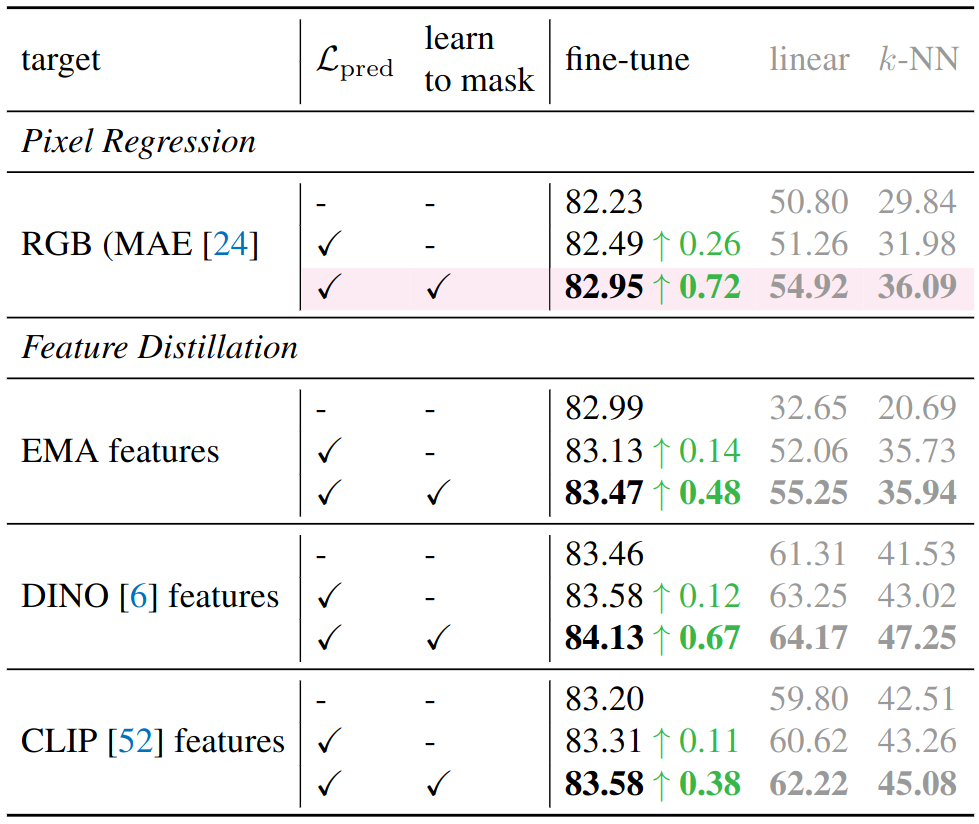
在针对重构目标的消融实验中,如上图所示:HPM 具有在各种学习目标下提升性能的能力。以像素回归为例,通过采用预测损失和 Easy-to-Hard 的掩码生成方式,微调后的 Top-1 准确率达到了82.95%,比 MAE 方法高出0.72%。值得注意的是,仅通过添加一个辅助解码器来预测每个补丁的重建损失,就能使微调准确率提高0.26%,达到82.49%。这验证了 HPM 的能力有助于提取出更好的特征表示。此外,原论文还对 Easy-to-Hard 的掩码策略和预测重构损失的计算方式进行了消融。根据实验数据,增加预训练任务的难度并不总是能带来更好的性能,相反从简单的预训练任务入手容易使模型快速收敛。而另一方面,正如预期的,BCE-Loss 在挖掘图块间的相对关系时是一个更好的选择,而不是像 MSE-Loss 那样关注重建损失的绝对值。因此,BCE 在性能上比使用绝对 MSE 高出0.18%。
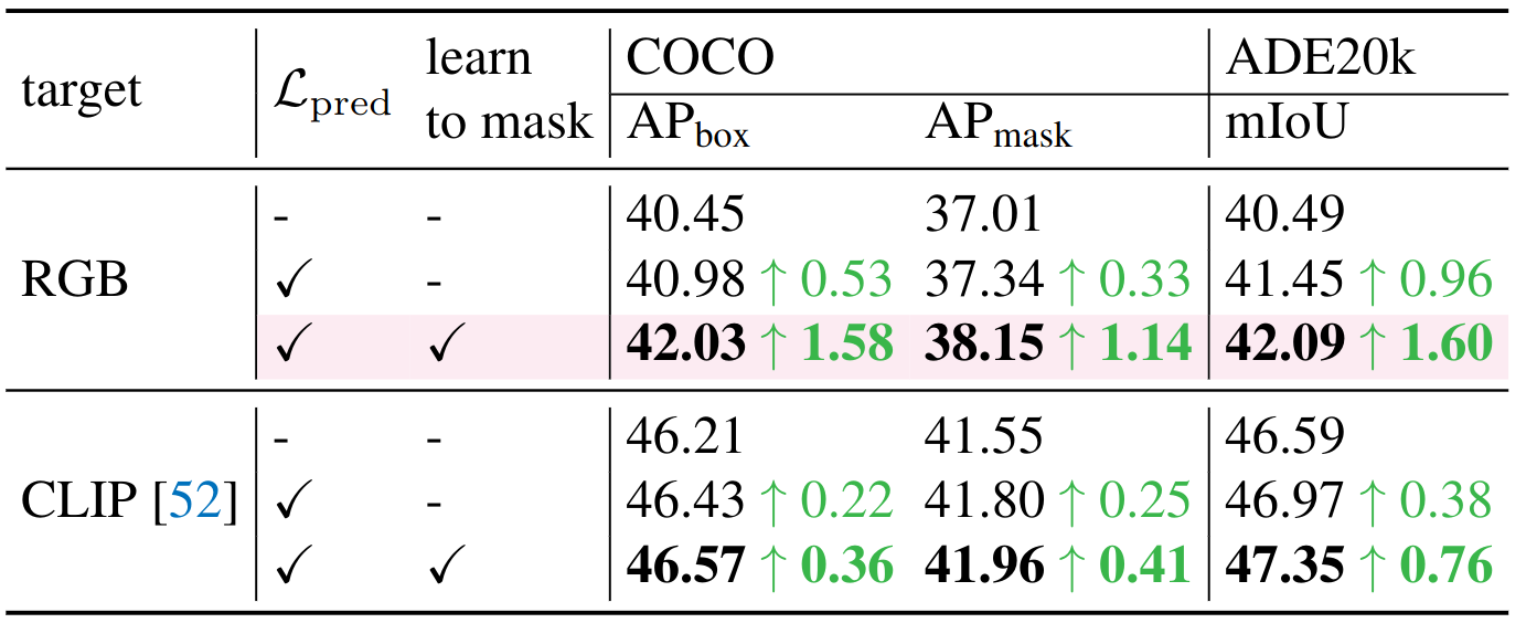
最后,在各种下游任务上,如图所示:COCO数据集上,其APbox提升超过+1.58,APmask提升超过+1.14;在ADE20k数据集上,其mIoU提升超过+1.60,均优于MAE基线模型。也就是说,以原始RGB像素作为学习目标是优于基线模型的。当使用CLIP特征作为学习目标时,它在COCO数据集上的APbox提升超过+0.36,APmask提升超过+0.41;在ADE20k数据集上,其mIoU提升超过+0.76,均优于基线模型。
总结
作为 Transformer 在 CV 领域应用的里程碑式的作品,Vit(Vision Transformer) 凭借其简单有效、高可扩展的优点被愈来愈多地认可和接受。目前,Vit 的代码在 github 上已经 开源 ,已有 1.2k 条 fork,9.2k star。于此同时,Vit 也被 Huggingface 社区所接收,有了专门统一的调度接口,详细清晰的文档说明以及来自世界各个国家和地区、各个数据集、各种训练方法的预训练参数。而随着 Vit 的蓬勃发展,与之相适应的各种视觉自监督任务也逐渐繁多,其中既有受 NLP 领域知识的启发,也有针对现存问题的改进。我们会发现,偶尔几次新工具的出现,就可能带动一个领域的爆火,并伴随与之相关的成百上千的新研究课题。另一方面,NLP 领域与 CV 领域的思想呈现出日益融合的趋势,这是否昭示着“大一统”模型在人工智能领域的出现?总之,Transformer 同时在 NLP 和 CV 领域大放异彩,表明它还具有非常巨大的潜力和非常广阔的前景等待人们探索、发现。